웹 인프라 거대 기업 Cloudflare가 Google의 AI 검색 정책에 정면으로 맞서고 있어요. 전 세계 웹사이트의 20%를 관리하는 Cloudflare CEO 매튜 프린스가 robots.txt 파일을 대규모로 업데이트하며 Google에게 변화를 압박하고 있는데요.

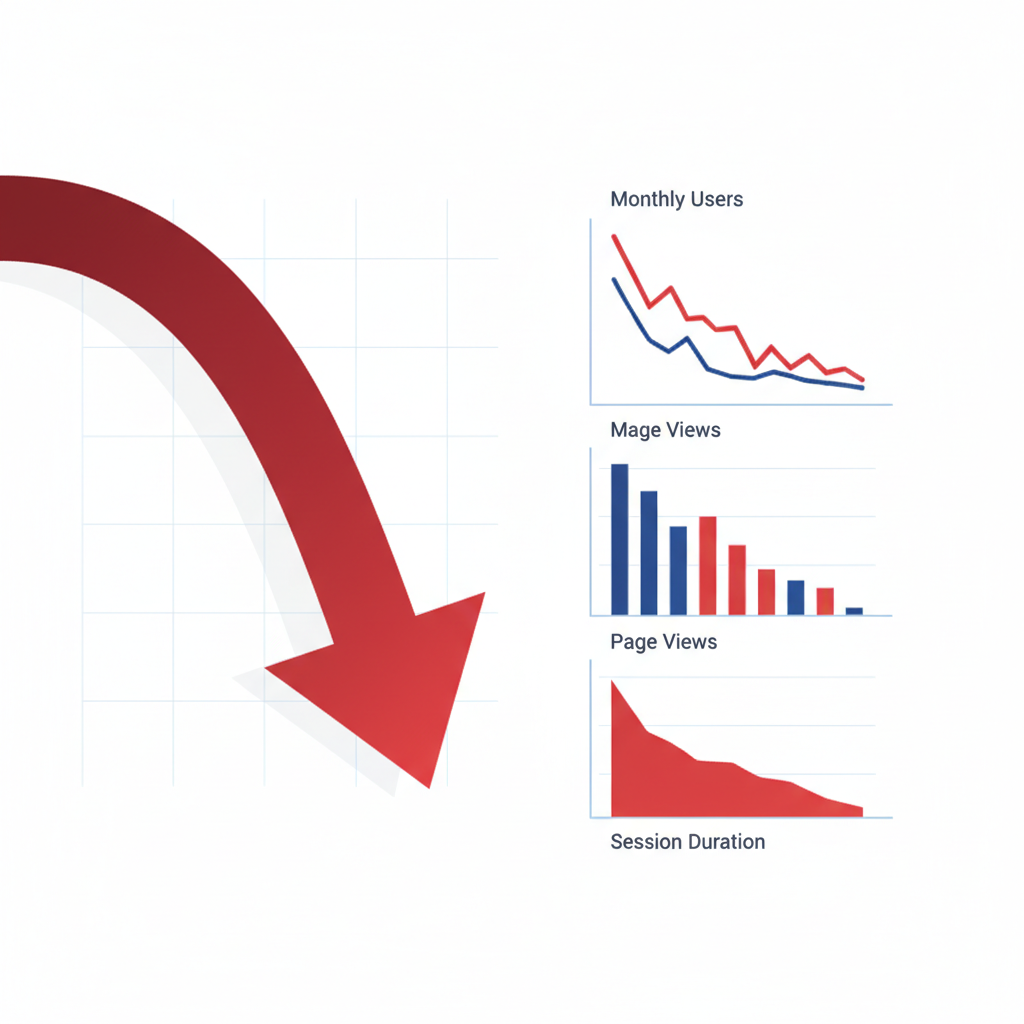
Google AI 오버뷰가 웹사이트 트래픽을 절반으로 줄였다
Google의 AI 오버뷰 기능이 웹사이트들의 수익 모델을 심각하게 위협하고 있어요. 퓨 리서치 센터의 7월 연구에 따르면, AI 오버뷰가 표시되는 검색 결과에서 사용자들이 실제 웹사이트를 클릭하는 비율이 8%로 떨어졌답니다. 기존 15%에서 거의 절반 수준으로 감소한 거죠.
더 심각한 건 대형 언론사들의 상황이에요:
- 뉴욕타임스, 비즈니스 인사이더 등 주요 매체들이 트래픽 급감을 보고
- 펜스케 미디어(할리우드 리포터, 롤링스톤 소유)는 제휴 링크 수익이 1년 만에 3분의 1 이상 감소
- 이로 인한 대규모 해고와 사업 전략 변경이 업계 전반에서 발생
Cloudflare의 혁신적인 대응책, 콘텐츠 시그널 정책
Cloudflare는 9월 24일 ‘콘텐츠 시그널 정책’을 발표하며 Google에 맞섰어요. 이 정책의 핵심은 전통적인 robots.txt 파일을 업데이트해서 웹 크롤링 목적을 세분화하는 것입니다.
새로운 robots.txt 형식에서는 세 가지 용도를 구분해요:
- search: 검색 인덱싱 및 검색 결과 제공 (AI 생성 요약 제외)
- ai-input: AI 모델에 실시간 콘텐츠 입력 (검색 AI 답변 생성용)
- ai-train: AI 모델 훈련 및 미세 조정
Cloudflare는 이미 380만 개 도메인의 robots.txt를 자동 업데이트했어요. 기본 설정은 검색은 허용, AI 훈련은 거부, AI 입력은 중립으로 설정되어 있답니다.
Google의 불공정한 번들링 전략이 문제의 핵심
Google이 다른 AI 기업들과 다른 점은 검색 크롤링과 AI 오버뷰 생성을 하나로 묶어버렸다는 거예요. 2023년부터 Google은 ‘Google-Extended’ 옵션을 통해 AI 모델 훈련용 크롤링은 차단할 수 있게 했지만, 검색 결과에 나타나려면 AI 오버뷰 생성도 함께 허용해야 합니다.
매튜 프린스 CEO는 이렇게 설명해요: “거의 모든 합리적인 AI 기업들이 공정한 경쟁 환경에서는 콘텐츠에 대한 비용을 지불할 의사가 있다고 말하고 있어요. 문제는 Google이 무료로 콘텐츠를 얻는데 다른 기업들은 모두 비용을 지불해야 한다면, 다른 기업들이 항상 불리한 위치에 놓이게 된다는 점입니다.”

법적 압박을 통한 변화 유도 전략
Cloudflare의 접근법은 단순히 기술적인 변경이 아니라 법적 압박을 가하는 전략이에요. 새로운 robots.txt 형식을 라이선스 계약처럼 만들어서 Google이 이를 무시할 경우 법적 리스크를 감수해야 하도록 설계했답니다.
프린스 CEO는 “Google의 법무팀이 이걸 보고 ‘어, 이제 우리가 웹의 상당 부분에서 이걸 적극적으로 무시하기로 선택해야 하는 상황이네’라고 말하고 있을 것”이라고 설명했어요.
실제로 펜스케 미디어는 이미 9월에 Google을 상대로 소송을 제기했고, 다른 출판사들도 비슷한 법적 조치를 고려하고 있어요.
웹 생태계의 새로운 패러다임 모색
Cloudflare는 단순히 Google에 맞서는 것이 아니라 웹의 미래 비즈니스 모델을 재정의하려고 해요. 회사는 Microsoft 소유의 Bing과 협력해 RAG(검색 증강 생성) 도구를 개발하고 있고, 웹사이트가 크롤러에게 스크래핑 비용을 청구할 수 있는 마켓플레이스도 실험 중이랍니다.
새로운 수익 모델의 가능성
앞으로 웹 생태계는 이런 방향으로 변화할 수 있어요:
- AI 기업들이 콘텐츠 사용에 대한 정당한 대가 지불
- 웹사이트 운영자들의 콘텐츠 사용 목적별 세밀한 제어
- 검색과 AI 요약의 분리를 통한 공정한 경쟁 환경 조성

변화의 시작점이 될 수 있는 중요한 시도
Google이 검색에서는 콘텐츠를 보여주되 AI 오버뷰에서는 제외하는 방식으로 정책을 바꾼다면, 이는 웹 생태계 전체에 긍정적인 변화의 시작점이 될 것으로 보여요. Cloudflare의 이번 시도가 성공하든 실패하든, 웹 콘텐츠의 공정한 사용에 대한 중요한 논의를 촉발시켰다는 점에서 의미가 크답니다.
출처: https://arstechnica.com/ai/2025/10/inside-the-web-infrastructure-revolt-over-googles-ai-overviews/